
Поиск конкретного элемента HTML на сайте — задача, с которой часто сталкиваются владельцы сайтов, разработчики и seo-специалисты. Рассмотрим, как найти элемент HTML на сайте по его CSS-классу и какие инструменты для этого нужны.
Для удобства статья разделена на две части:
- Теоретическую, в которой понятным языком рассказываем о парсинге, способах его работы и авторитетных источниках для более подробного изучения информации.
- Практическую, где показываем, как в SiteAnalayzer и Screaming Frog найти нужный HTML-тег на сайте.
Теория
HTML и его атрибуты
Атрибуты в HTML — это дополнительные параметры, которые помогают уточнять свойства тегов. Они всегда записываются внутри открывающего тега и состоят из имени атрибута и значения. Атрибуты, которые встречаются чаще всего:
- href – ссылка;
- src – путь к изображению, видео, скрипту;
- alt – альтернативный текст;
- id – уникальный идентификатор;
- class – класс для CSS и JS;
- style – встроенные CSS-стили;
- title – всплывающая подсказка;
- target – поведение ссылки (_blank — новая вкладка);
- type – тип элемента;
- placeholder – текст-подсказка в поле ввода;
- disabled – делает элемент неактивным;
- readonly – запрет редактирования поля.
Подробнее почитать об атрибутах можно в документации MDN. В данной статье мы будем искать элемент по атрибуту class.
Парсинг и поисковые правила
Веб-скрейпинг (парсинг) — это процесс автоматизированного сбора данных с веб-страниц по заранее заданным правилам. Он используется для анализа контента, мониторинга цен, сбора отзывов, парсинга новостей и других задач.
Методы поиска и извлечения данных
Для извлечения нужной информации веб-скрейперы используют различные методы структурированного поиска:
-
XPath — язык запросов для XML и HTML-документов. Доступ к содержимому, которое ищем, происходит благодаря навигации по DOM через описание пути к нужному элементу (Document Object Model — структура веб-страницы, позволяющая программам взаимодействовать с содержимым, внешним отображением и структурой). Работа схожа с навигацией в операционных системах, когда мы ищем какой-то файл, находящийся в одной из папок. На примере сайта выглядит так: div→div→p: мы ищем элемент p, он является дочерним у div, который также дочерний для другого div. В формате выражения: //div/div/p.
Пример: если нужно найти все абзацы
<p>внутри<div class="content">, используем XPath-запрос://div[@class="content"]/pИсточник: документация от MDN
-
XQuery — язык запросов, основанный на XPath, но с расширенными возможностями фильтрации и обработки данных. Чаще используется для сложных XML-документов.
Подробнее: официальная документация XQuery
-
CSS-селекторы (CSSPath) — способ поиска элементов на странице по их CSS-классам, тегам и атрибутам. Этот метод проще, чем XPath, но менее гибкий. В отличие от XPath, CSS-селекторы работают только вглубь документа. Для поиска используются элементы, CSS-классы (псевдоклассы и псевдоэлементы тоже), идентификаторы, атрибуты, потомки и дочерние элементы. Также допускается создание комбинаций из перечисленных элементов для более точного поиска.
Пример: найти все
<p>, находящиеся внутри<div class="content">:div.content pПодробнее: MDN Web Docs по CSS-селекторам
-
HTML Templates — метод, позволяющий извлекать информацию на основе заранее заданных HTML-шаблонов. Представляет собой комбинацию HTML для описания шаблона поиска нужного фрагмента.
-
RegExp (регулярные выражения) — формальный язык регулярных выражений для поиска информации в большом количестве текста.
Пример: если нужно найти все email-адреса в тексте:
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}Подробнее: документация по регулярным выражениям на MDN
Почему нельзя парсить HTML с помощью регулярных выражений (RegExp)?
Этот вопрос часто возникает у тех, кто начинает изучать парсинг данных. Разберемся, почему RegExp не подходят для этой задачи.
Ранее мы уже упоминали обсуждение на Stack Overflow, где подробно объясняются проблемы использования регулярных выражений для работы с HTML. Основная причина в том, что HTML — это не просто текст, а сложная структура с вложенными элементами, которые RegExp не умеют правильно обрабатывать.
Кроме того, об этом пишут и в более серьезных источниках. Например, Джеффри Фридл, автор книги «Регулярные выражения»:
«Если вы пытаетесь извлекать данные из XML или HTML с помощью регулярных выражений, вам, вероятно, стоит пересмотреть свой подход. Регулярные выражения отлично подходят для поиска простых строковых шаблонов, но HTML — это вложенный, рекурсивный язык, который требует полноценного парсера для корректной обработки.»
Обход блокировок при парсинге
На большинстве сайтов стоит защита от парсинга, чтобы не перегружать сервер. При попытке спарсить программа не будет отображать информацию и наполнится ошибками по каждому урлу. Обход защиты для каждого сайта свой, но наиболее популярными способами являются:
- Ротация IP-адресов. Использование прокси-серверов позволяет менять IP-адрес с каждым запросом, делая скрейпер менее заметным. Это снижает вероятность блокировки за подозрительную активность.
- Смена User-Agent. В заголовках HTTP-запросов указывается информация о браузере и устройстве. Регулярное изменение User-Agent помогает имитировать реальные посещения с разных устройств и избежать детектирования. Мы пользуемся этим способом.
- Работа с JavaScript и AJAX. Многие сайты загружают контент динамически. Для парсинга таких страниц используются headless-браузеры, например, Selenium, Puppeteer или решения с рендерингом JavaScript.
- Обход CAPTCHA. Некоторые сайты требуют прохождения CAPTCHA. Для автоматического решения можно использовать сервисы вроде 2Captcha, Anti-Captcha.
- Задержка между запросами. Введение случайных пауз между запросами имитирует поведение реального пользователя и снижает риск обнаружения автоматического сбора. Такое мы тоже использовали, меняя скорость и потоки.
Практика
Изучив парсинг чуть лучше, перейдем к практике — будем искать элементы HTML по CSS-классам, пользоваться будем парсерами Screaming Frog SEO Spider и SiteAnalyzer.
Задача
Для примера возьмем сайт lenwood.ru и найдем все элементы с CSS-классом:
“wrapper-calculator-block”Для решения данной задачи мы можем воспользоваться XPath и CSSPath.
Site-analyzer в своей документации разместили примеры кода для извлечения данных. В примере под номером 60 есть XPath-правило для поиска элементов по CSS-классу:
//span[@class="example"]SiteAnalyzer
Инструмент для комплексного анализа веб-сайтов, оценивающий SEO-параметры, техническую корректность (например, скорость загрузки, адаптивность) и структуру контента, выявляет ошибки. Скачать и ознакомиться получше можно на официальном сайте.
В статье по поиску текста мы базово познакомились с интерфейсом и функционалом SiteAnalyzer. Разобрались, как добавлять правила, поэтому повторяться не будем. Если не знаете, как добавить правило, то ознакомьтесь с разделом по поиску слов в Site-analyzer.
Для поиска нужного нам элемента подойдет правило:
div[class=wrapper-calculator-block]. Заносим его в настройках и запускаем парсинг.
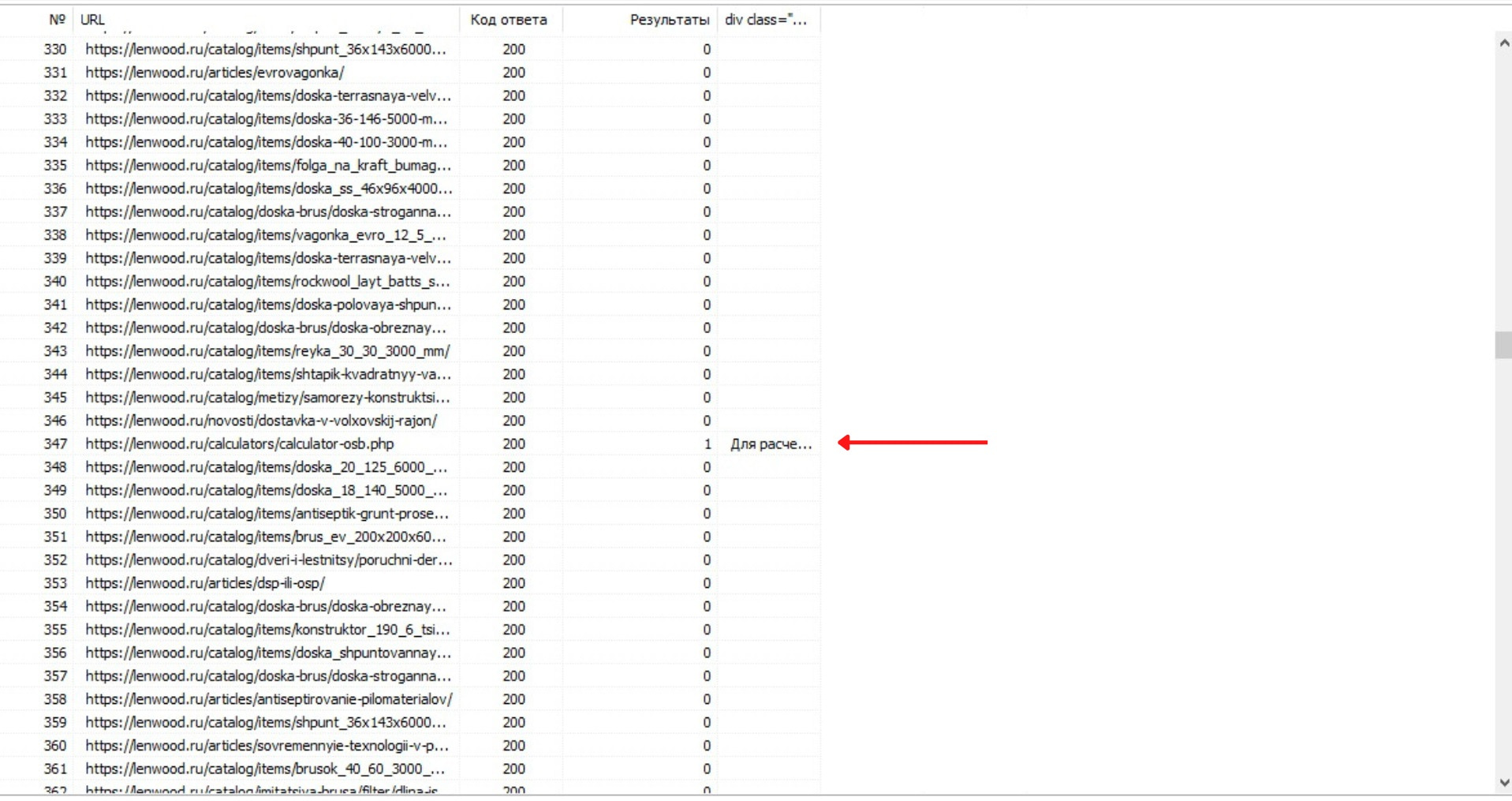
В таблице мы видим следующее: код ответа сервера, 1 столбец. Результаты, отображается число, если есть, 2 столбец. Текстовый фрагмент, где встречается искомая фраза, 3 столбец. Мы нашли все элементы с данным классом через данный парсер, переходим к следующему.
Screaming Frog SEO Spider
Мощный краулер для аудита сайтов. Он сканирует страницы, проверяет метатеги, заголовки, ссылки и структуру, находит ошибки (битые ссылки, дубли контента), создает XML-карты и синхронизируется с Google Analytics и Search Console. Инструмент используют для SEO-оптимизации, анализа конкурентов и сбора данных для отчетов.
«Лягушка» — один из лидеров в сфере парсинга и обладает очень широким функционалом. Хотим показать вам «Visual Custom Extraction» — функционал, суть которого в визуальном выборе нужного элемента на отрисованной веб-странице или в HTML. Можно работать как с отрисованной веб-страницей, так и с HTML версткой, что очень удобно, особенно если вы еще «плаваете» в составлении правил для парсинга.
Начнем с того, что сразу поменяем User-Agent. Для этого открываем: Configuration/Crawl Config/User-Agent. Если забыли, где это находится, то мы подробно разбирали смену юзер агента в статье про поиск слова на сайте. После изменения агента в том же разделе Configuration/Crawl Config/ открываем Custom/Custom Extraction и добавляем новое поисковое правило.
После этого у нас появилась строка с шаблоном для добавления правила. Можем изменить название и прописать правильно для поиска вручную, но мы воспользуемся удобным инструментом автоматического подбора правила для поиска. Для этого нажимаем на иконку глобуса.
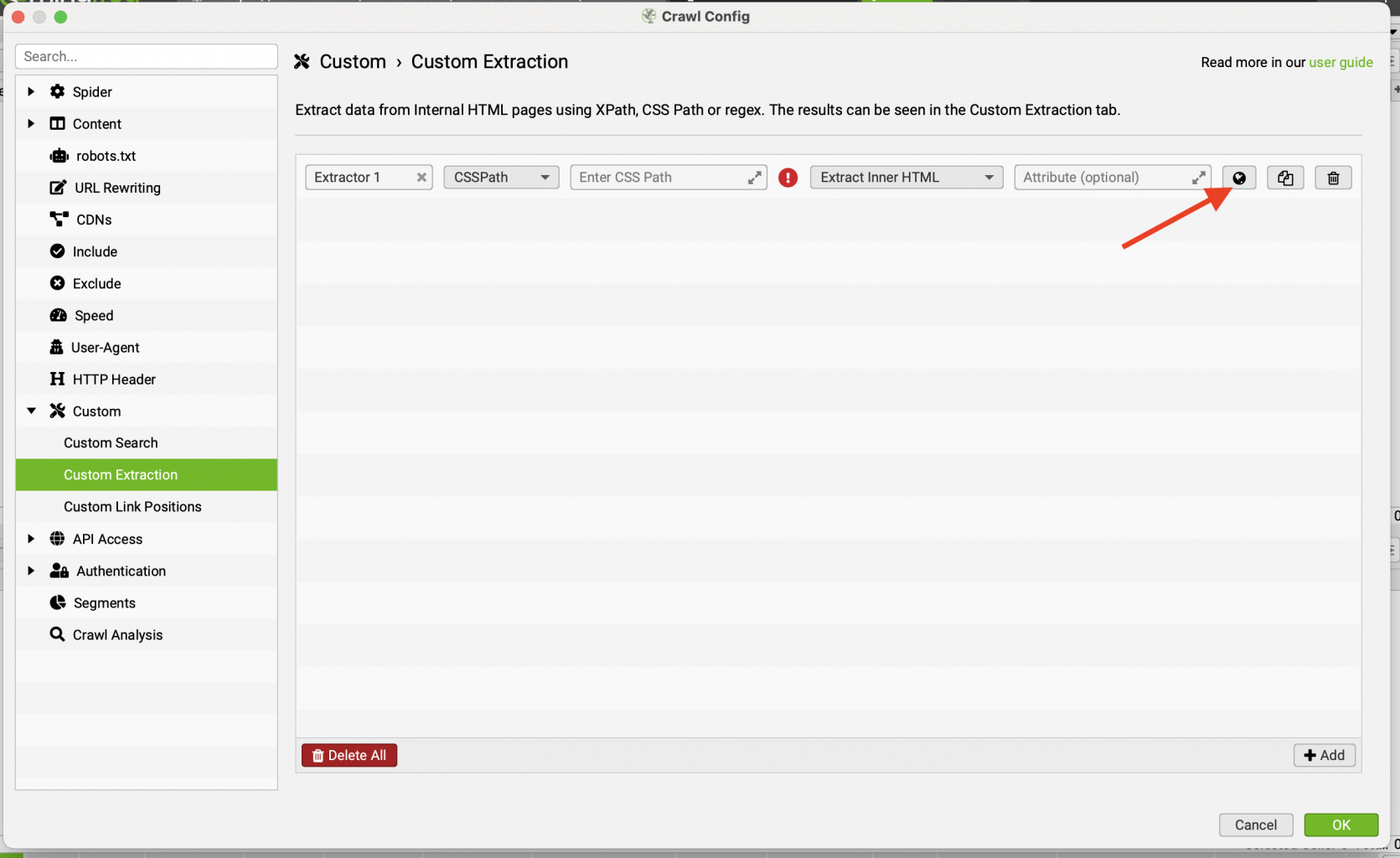
После клика снова откроется дополнительное окно, в котором мы вводим URL страницы, на которой есть интересующий нас элемент. Тут мы можем переключаться среди вкладок:
- Rendered HTML – вкладка отображает HTML-код, который был уже обработан браузером. Это тот код, который на самом деле отображается на странице после всех стилей, скриптов и динамических изменений.
- Source HTML – вкладка показывает исходный HTML-код страницы, то есть код, который был загружен на веб-страницу до обработки браузером. Это обычно «чистый» код, без учёта CSS и JavaScript изменений.
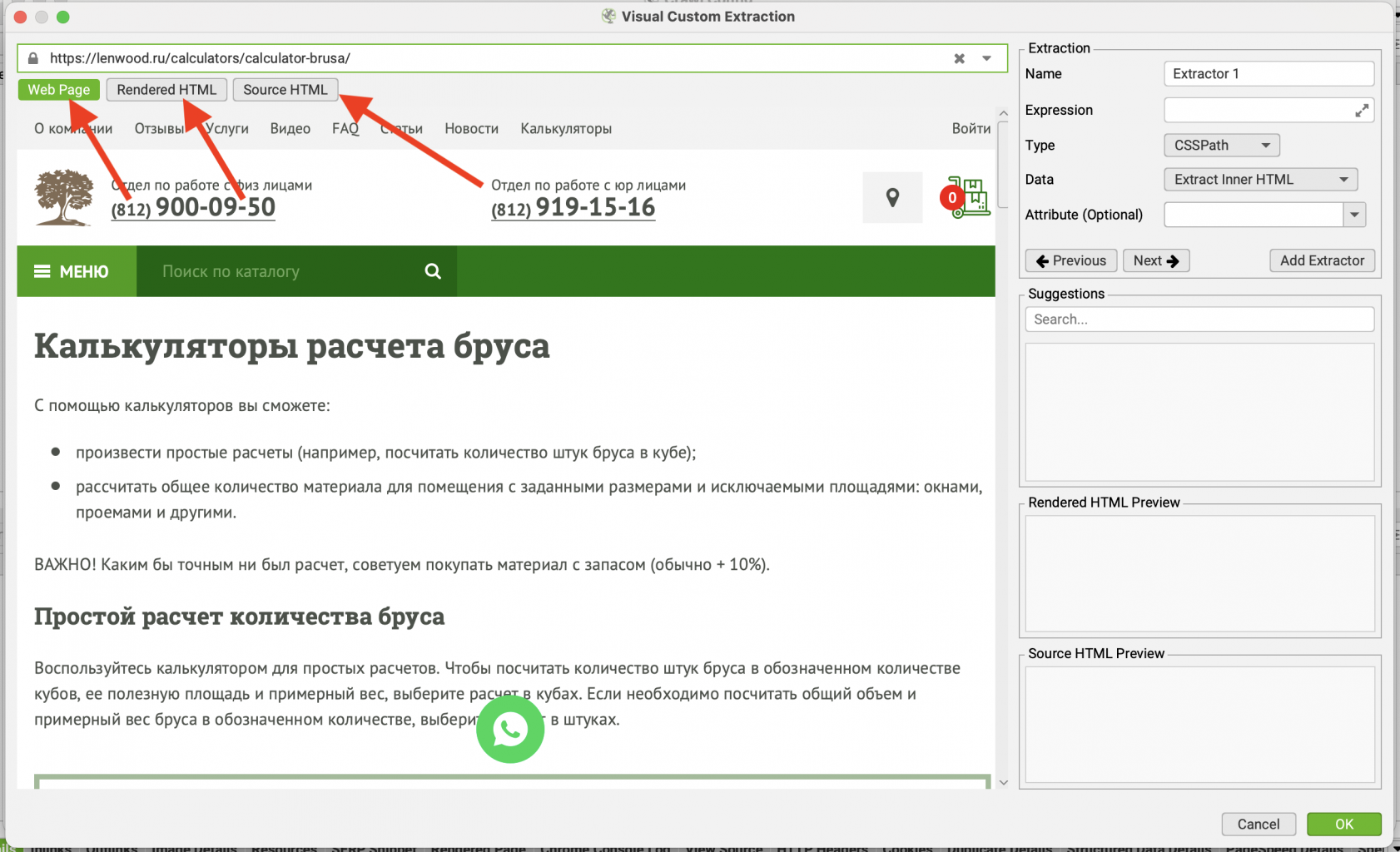
- Web Page – отображает саму веб-страницу — как она выглядит в браузере с учётом всех элементов, стилей и визуальных изменений, происходящих на странице.
Для демонстрации нам потребуется Web Page, где находится отрисованная страница. Работа с данной вкладкой напоминает просмотр страницы в браузере. При клике на элементы страницы, правила для их поиска отображаются в графе справа.
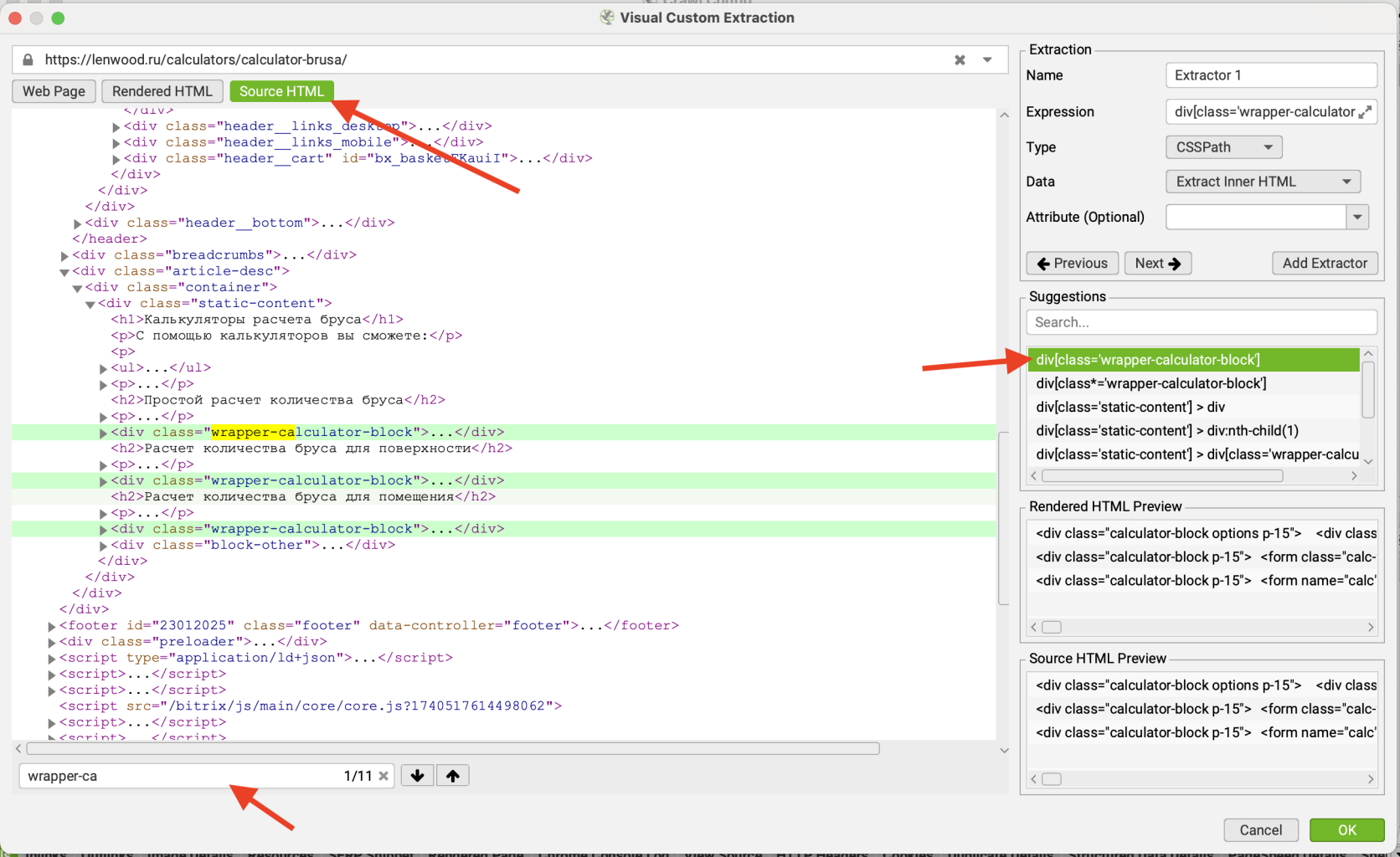
Вернемся на вкладку «Source HTML» и в верстке найдем нужный нам элемент — <div class=”wrapper-calculator-block”> (кстати, это можно сделать через поиск). В большинстве способ подбора правила через source является удобнее, так как позволяет сразу найти нужный элемент. Но если у вас сложности с HTML, то можете воспользоваться и рассмотренным выше вариантом выбора через визуальный интерфейс. Мы сразу нашли нужный нам элемент и в графе справа «Suggestions» появилось поисковое правило. Осталось только выбрать его и нажать “Ok”.
Правило появилось в нашем списке. Снова жмем «Ok» и сворачиваем настройку правил. Копируем URL нужного нам сайта и добавляем его в поле «Enter URL to spider» рядом с логотипом программы, нажимаем «Start». Будет запущен парсинг сайта. Время, как и в случае с SiteAnalyzer зависит от количества страниц на сайте.
После завершения парсинга вновь жмем по вкладке «Overview» для просмотра результатов.

Поиск HTML-элементов на сайте по CSS-классу – важная задача для веб-разработчиков, SEO-специалистов и владельцев сайтов. В статье мы рассмотрели, как ее выполнить с помощью двух популярных парсеров: Screaming Frog и SiteAnalayzer.

Кстати, если вам нужно найти на сайте конкретное слово или словосочетание, то у нас есть отдельная статья на эту тему.