

Если ваша организация изменила адрес или номер телефона и его нужно поправить на всех страницах сайта, необязательно просматривать каждую вручную, чтобы найти те, где есть устаревшая информация. Для этого можно воспользоваться автоматизированными способами поиска нужного слова или словосочетания. В этой статье расскажем о наиболее удобных, на наш взгляд.
Поиск слова
Поиск слова или словосочетания - то, с чем сталкивается большая часть пользователей. Например, у вас на сайте поменялась какая-то информация и везде ее нужно изменить. Это может быть производитель оборудования или другая статичная информация. Поиск можно осуществить двумя способами: поисковыми операторами и парсерами.
Поисковые операторы
В поисковых системах есть специальные символы, слова и фразы для конкретизации запроса, они называются поисковыми операторами. Операторов большое количество, ознакомиться с ними можно в документации используемого поисковика: Яндекса или Google.
Нас интересует оператор, который позволяет найти нужное словосочетание в пределах одного сайта, - site:.
Используется он так: site: доменное_имя.ru нужное слово.
Обратите внимание, что для того, чтобы найти упоминания конкретной фразы ее нужно выделить в кавычки. Без кавычек поисковик покажет все похожие вхождения.
Работоспособность данного оператора проверим через поисковые системы Google и Яндекс.

Чтобы по своему запросу в Google или Яндексе получить подходящие результаты, можно использовать не только поисковые операторы, но и специальные символы. Одни из таких — кавычки. Если заключить в них фразу, поисковая система будет искать именно ее, а не отдельные слова в разных комбинациях. Если кавычки не использовать, поисковики могут показать страницы, которые связаны с отдельными словами из запроса.
Рассмотрим на примере: найдем страницы, на которых встречается фраза пример перевода. Вбиваем ее в поисковик без кавычек. Google и Яндекс помимо подходящих страниц нашли:
- Страницы, на которых упоминается отдельные слова из фразы в разных формах: перевод, переводов, пример, примеров, примера и так далее.
- Страницы, на которых упоминаются оба слова из фразы, но они никак не связаны друг с другом.
Когда заключили фразу в кавычки ("пример перевода"), получили меньшее количество страниц, чем в первый раз. Но фраза на них упоминается именно в той форме, которой мы вбили ее в поисковик.
Но это не показывает, что какой-то вариант лучше или хуже. Все зависит от целей поиска. И кстати, кавычки — не единственный спецсимволы, которые помогают уточнить запрос. При желании можете ознакомиться с полным списком символов в Яндексе и Гугл.
Использование оператора site: в Google
Для примера взяли сайт бюро переводов ТранЭкспресс и попытались найти на нем несколько фраз. Одна из них - “подсчет слов”.
Чтобы проиллюстрировать пример точных вхождений и всех схожих фраз мы поочередно вставляем в поисковую строку:
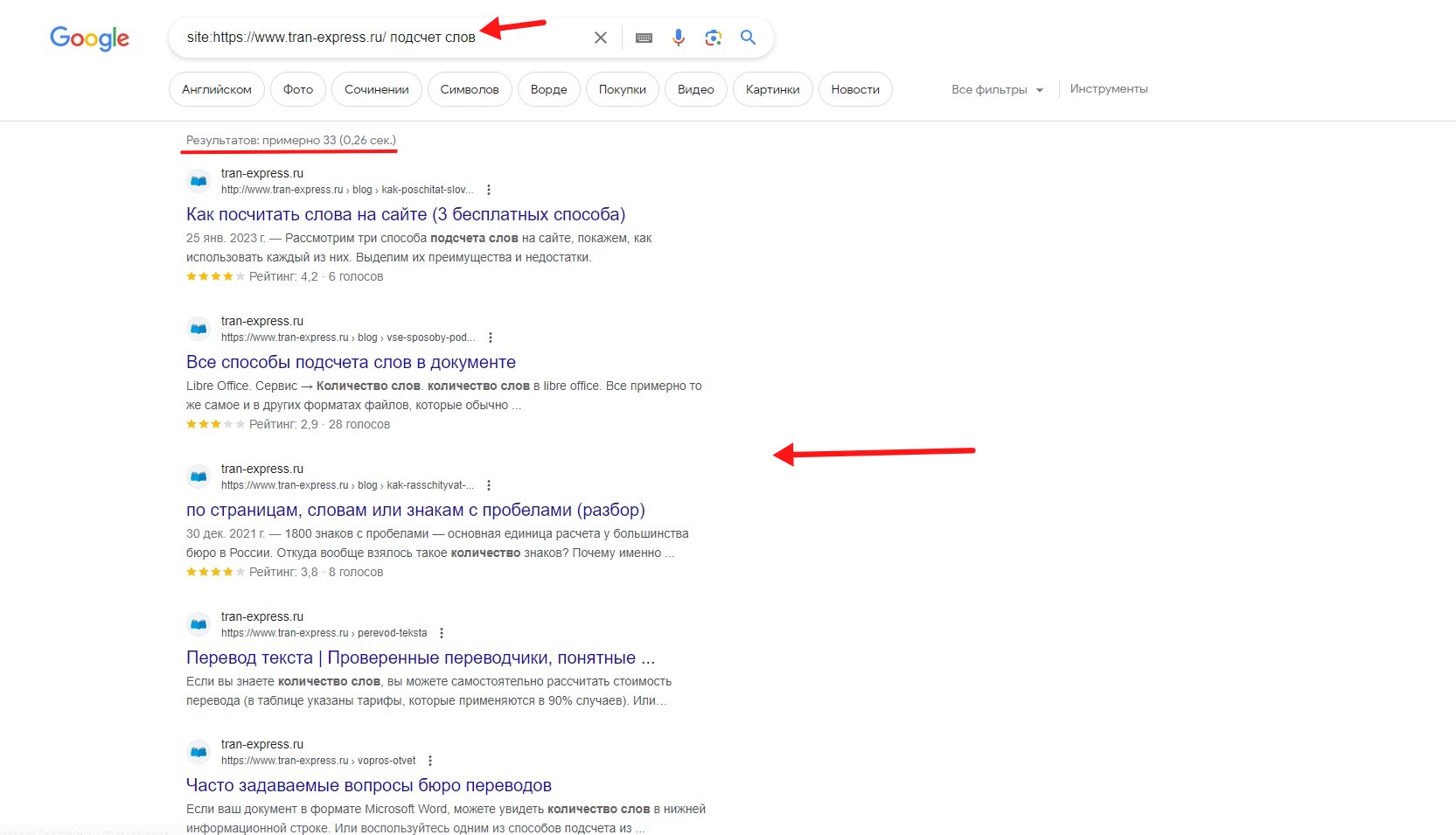
- site:https://www.tran-express.ru/ подсчет слов;
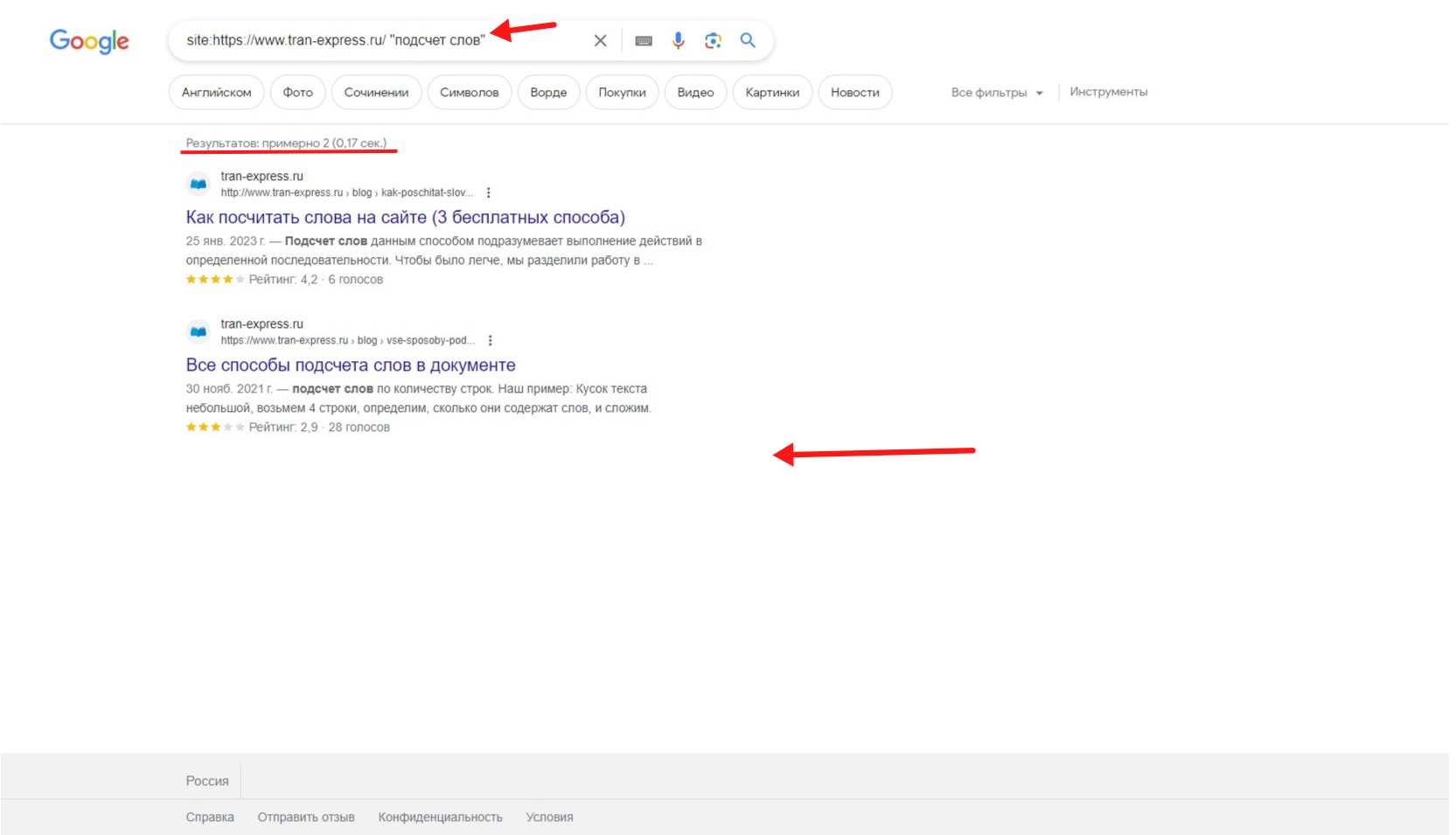
- site:https://www.tran-express.ru/ "подсчет слов".
Google выдал список страниц сайта, на которых встречается эта фраза.
Мы использовали site:https://www.tran-express.ru/ подсчет слов. Фраза была без кавычек и в поиске появилось 33 результата.
Пробуем site:https://www.tran-express.ru/ "подсчет слов". На запрос фразы в кавычках Google показал только 2 результата.
Изучив поисковую выдачу Google, рассмотрим, что выдаст Яндекс.
Использование оператора site: в Яндекс.
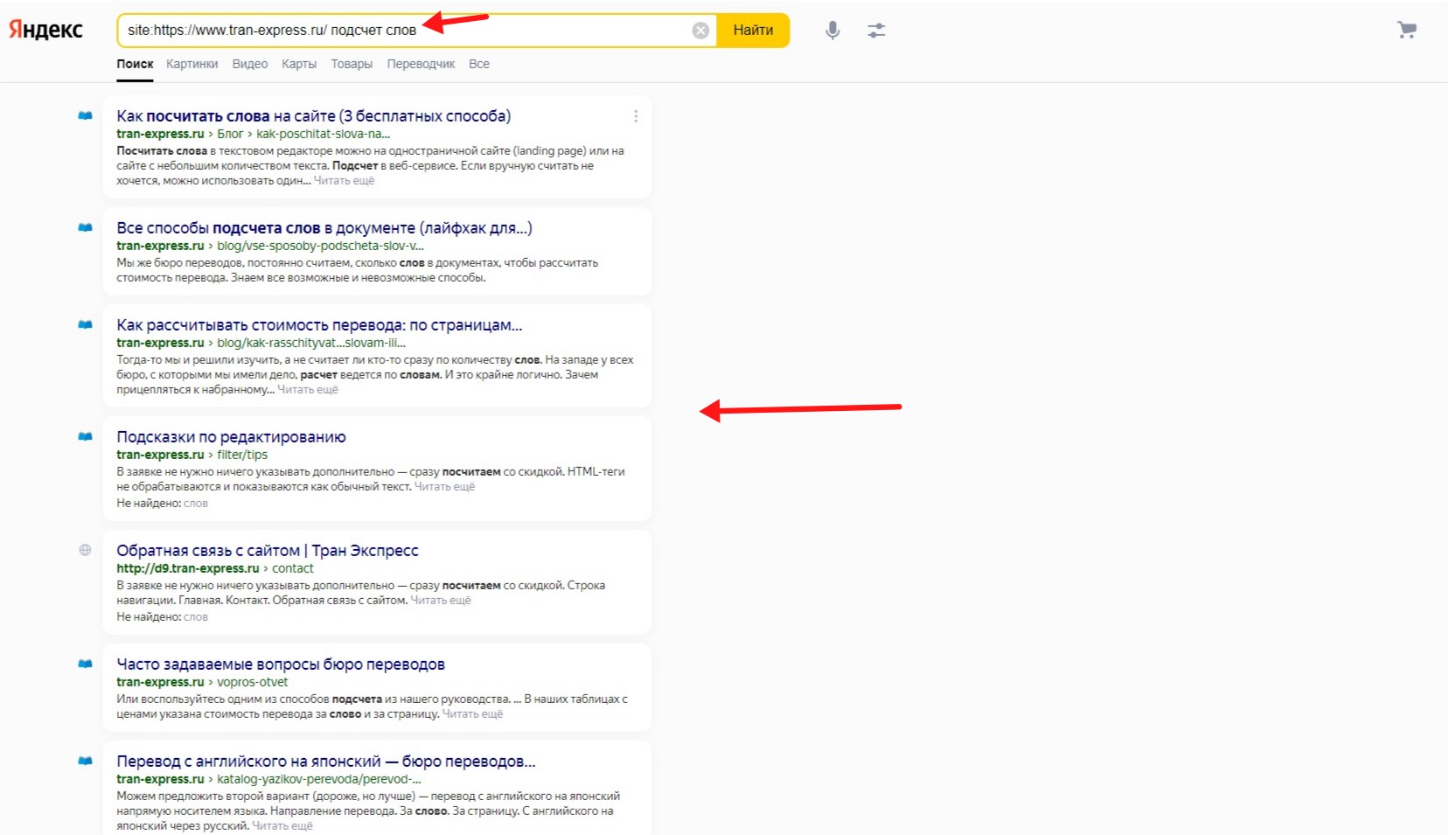
Для проверки работоспособности поискового оператора в Яндексе будем искать такие же фразы, что и в гугле.
site:https://www.tran-express.ru/ подсчет слов. К сожалению, Яндекс не выводит количество результатов, но на скриншоте видим, что первая страница поиска заполнена при поиске фразы без кавычек.
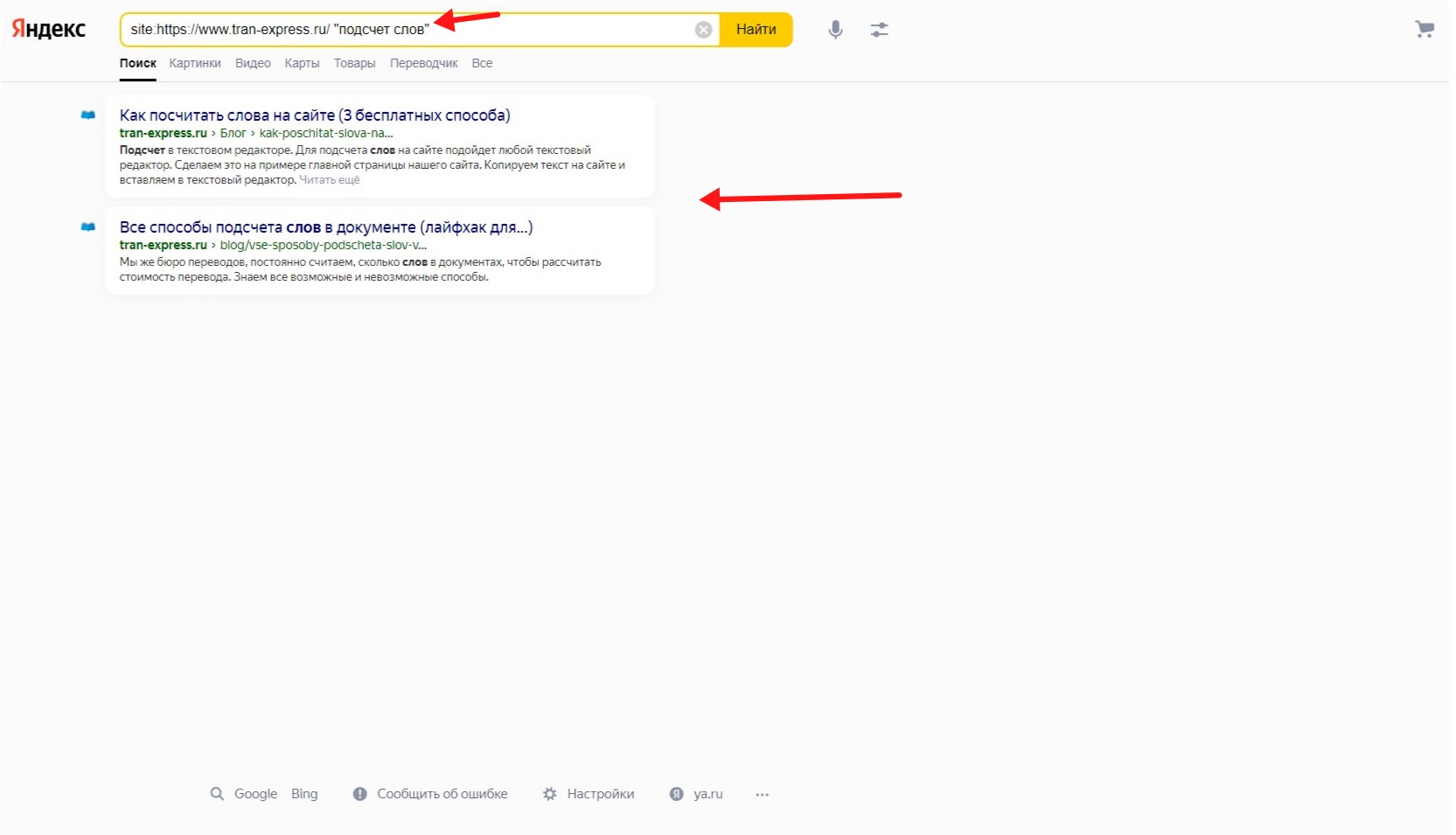
site:https://www.tran-express.ru/ "подсчет слов". В кавычках только 2.
Использовать этот подход рационально, если нужно:
- проверить, отображаются ли конкретные страницы в поиске;
- оперативно получить страницы с использованием конкретной фразы;
- найти определенную информацию на одной-двух страницах.
Если хотите получить полный список страниц с вашей фразой, следует воспользоваться подходом с парсерами, о котором рассказываем ниже.
Парсеры для поиска слов
Для поиска нужной информации на сайте можно воспользоваться парсерами - программами, которые собирают информацию с веб-ресурса и выдают ее в нужном формате. Парсеров существует большое количество: платные и бесплатные, для сбора цен, для совместных покупок и так далее.
Начнем с того, что поиск в парсерах осуществляется на базе поисковых правил. Подробно о поисковых правилах мы рассказываем во второй части, т.к. для базовой работы с парсерами эта информация не является необходимой.
Мы будем взаимодействовать с двумя парсерами: SiteAnalyzer и Screaming Frog SEO Spider
SiteAnalyzer
SiteAnalyzer - программа для SEO-аудита. SiteAnalyzer ранее предлагал бесплатную лицензию за регистрацию. На сегодняшний день у программы также две версии: бесплатная с урезанным функционалом и полная, доступная после покупки лицензии. Ознакомиться со стоимостью лицензий и ограничениями бесплатной версии можете на сайте.
Для работы необходимо скачать программу и зарегистрироваться, процесс скачивания и регистрации пропустим, а остальные этапы пошагово рассмотрим.
Шаг 1. Настройка и получение информации о сайте
Нужно получить список всех страниц. Для этого открываем SiteAnalyzer и вставляем урл сайта. Затем нажимаем на кнопку "Старт". Запускается проверка сайта, длительность зависит от количества страниц на нем.
После проверки вкладки программы заполняются информацией: всеми ссылками с сайта, временем отклика страниц, SEO-информацией и другими данными. Подробно прочитать о каждой из вкладок можно в документации SiteAnalayzer.
В редких случаях парсинг может не получиться. Причины у этого могут быть разные. Например, установлена защита на хостинге. Если вы столкнулись с тем, что сайт не парсится, попробуйте сменить User-Agent в SiteAnalayzer.
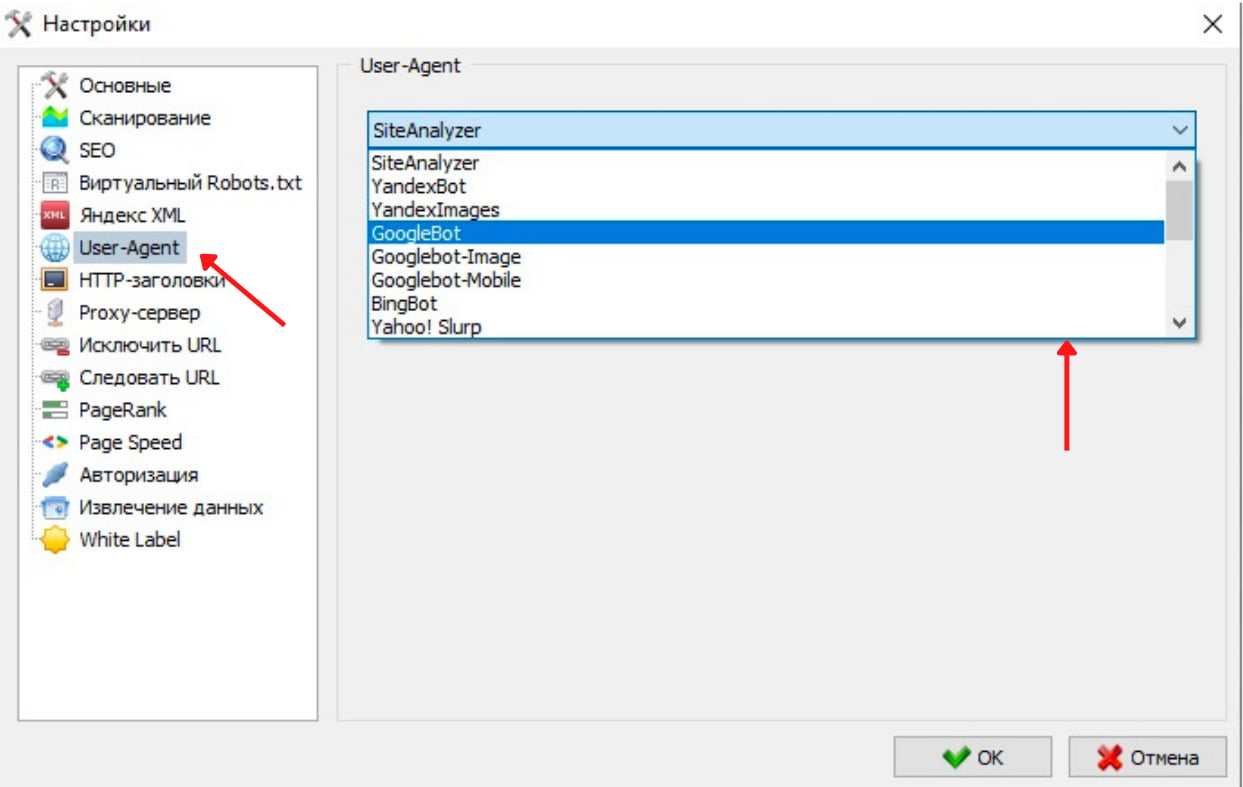
User-Agent - это строка, которую браузер, а в нашем случае парсер, отправляет на сервер при запросе веб-страниц. Она содержит информацию об операционной системе, браузере и другие данные.
Чтобы сменить User-Agent, перейдите в настройки, далее кликните на "User-Agent" и выберите YandexBot или GoogleBot. После этого повторите парсинг.
Шаг 2. Поиск
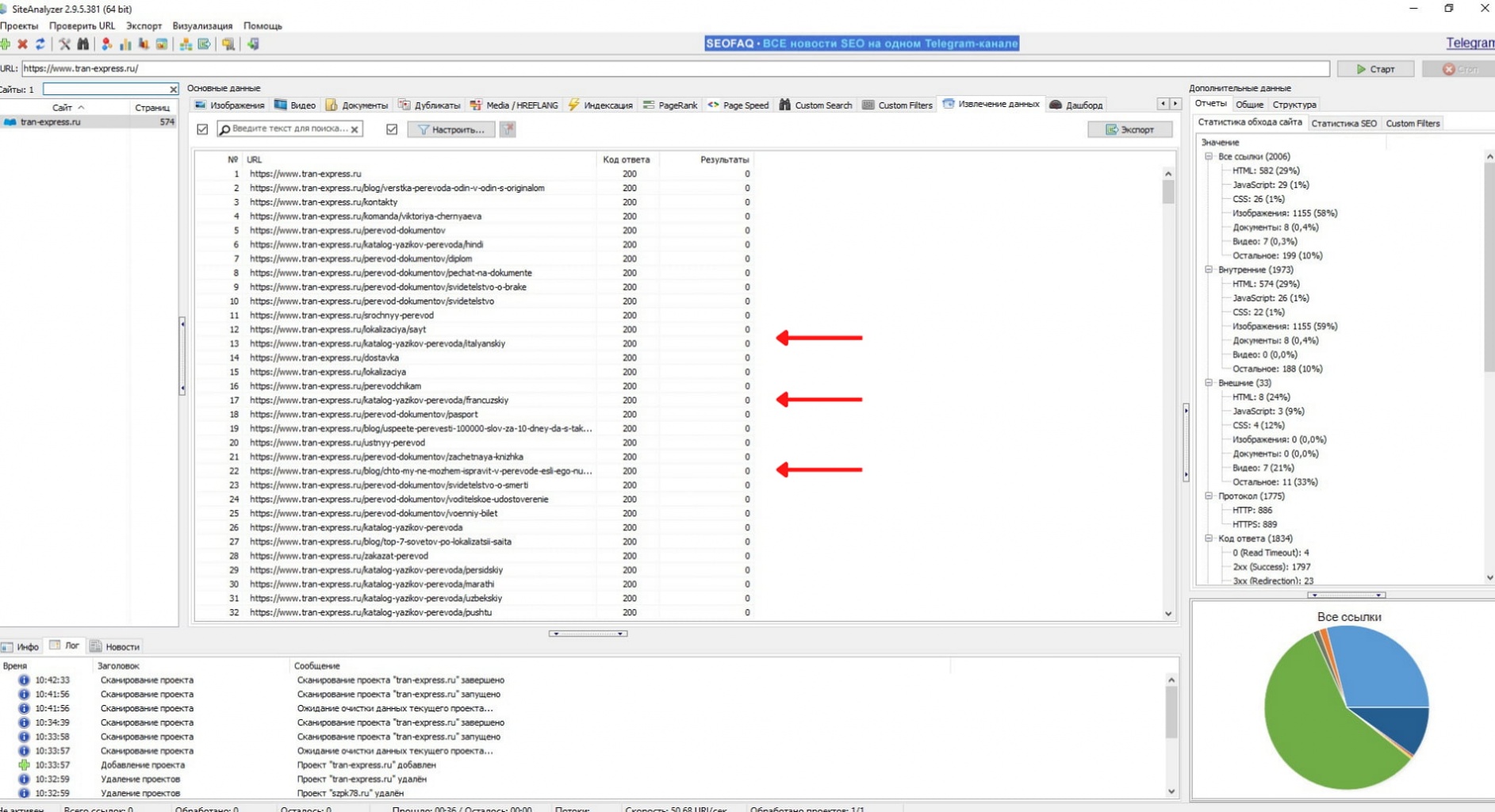
Если парсинг прошел успешно и вы получили основную информацию о сайте, переходим к следующему шагу - поиску интересующей фразы. Для этого переходим во вкладку “Извлечение данных”.
Если добавлены правила для поиска, в графе "Результаты" выводится количество. Мы не задали ни одного правила, поэтому столбец пустой.
Перейдем к этапу внесения правил.
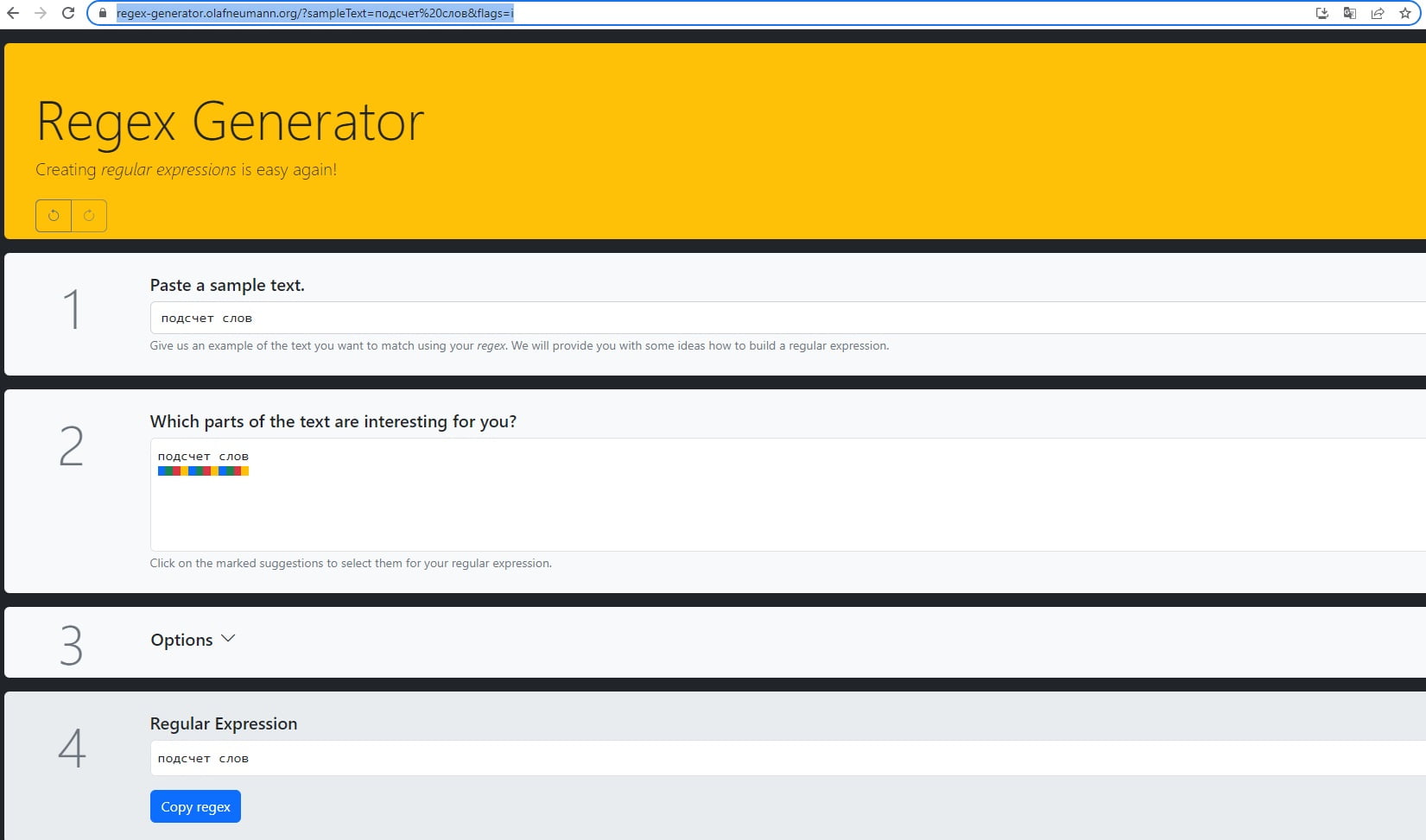
Мы хотим найти словосочетание “подсчет слов”. Для этого воспользуемся методом RegEx. Важный момент, мы используем RegEx (регулярные выражения), потому что, на момент написания статьи, в функционале данного парсера поиск слов и словосочетаний был возможен только таким образом. Если кратко, то использовать регулярные выражения для парсинга HTML не рекомендуется, поскольку HTML обладает вложенной и рекурсивной структурой, которую RegEx не способен корректно обработать.
Чтобы найти фразу, необходимо составить регулярное выражение. Разумеется, это можно сделать самостоятельно, прочитав документацию. Но самым простым вариантом является использование RegEx генератора или нейросети. В данном случае правило является абсолютно идентичным искомому тексту.
RegEx можно использовать для поиска отдельных HTML тегов. Также он позволяет исключать из поиска отдельные элементы, для этого нужна конструкция: [^исключение] - в квадратных скобках указывается искомый элемент, а ^ означает исключение. Правилом [^0-9] мы исключаем из поиска все цифры.
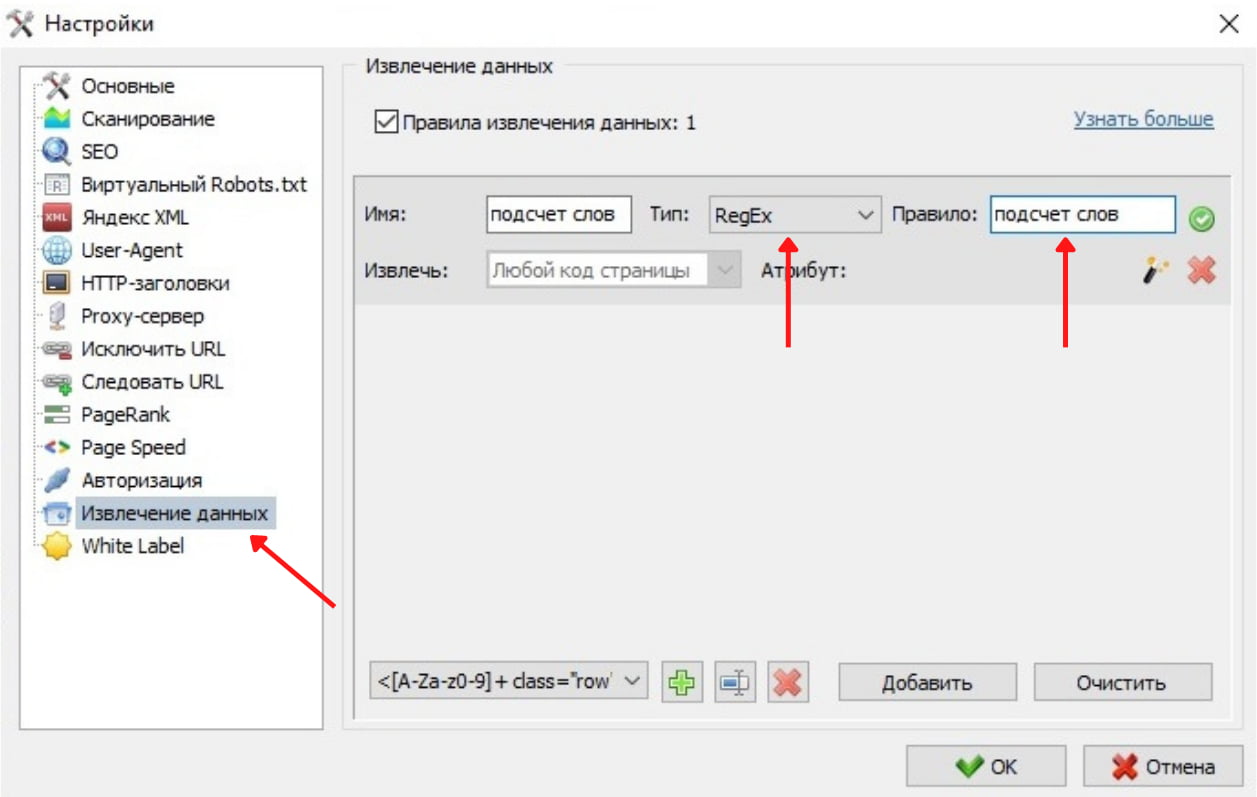
Возвращаемся к SiteAnalyzer и выбираем на верхней панели “Проекты”, в открывшемся окне нажимаем “Настройки”.
Добавляем название правила. Оно может быть любым, но для наглядности лучше использовать формулировку самого правила. Выбираем RegEx и вносим правило. Важно поставить галочку у “Правила извлечения данных”.
Сохраняем и возвращаемся на вкладку “Извлечение данных”. Мы добавили одно правило, появилась дополнительная графа с ним. Нажимаем “Старт” и запускаем проверку.
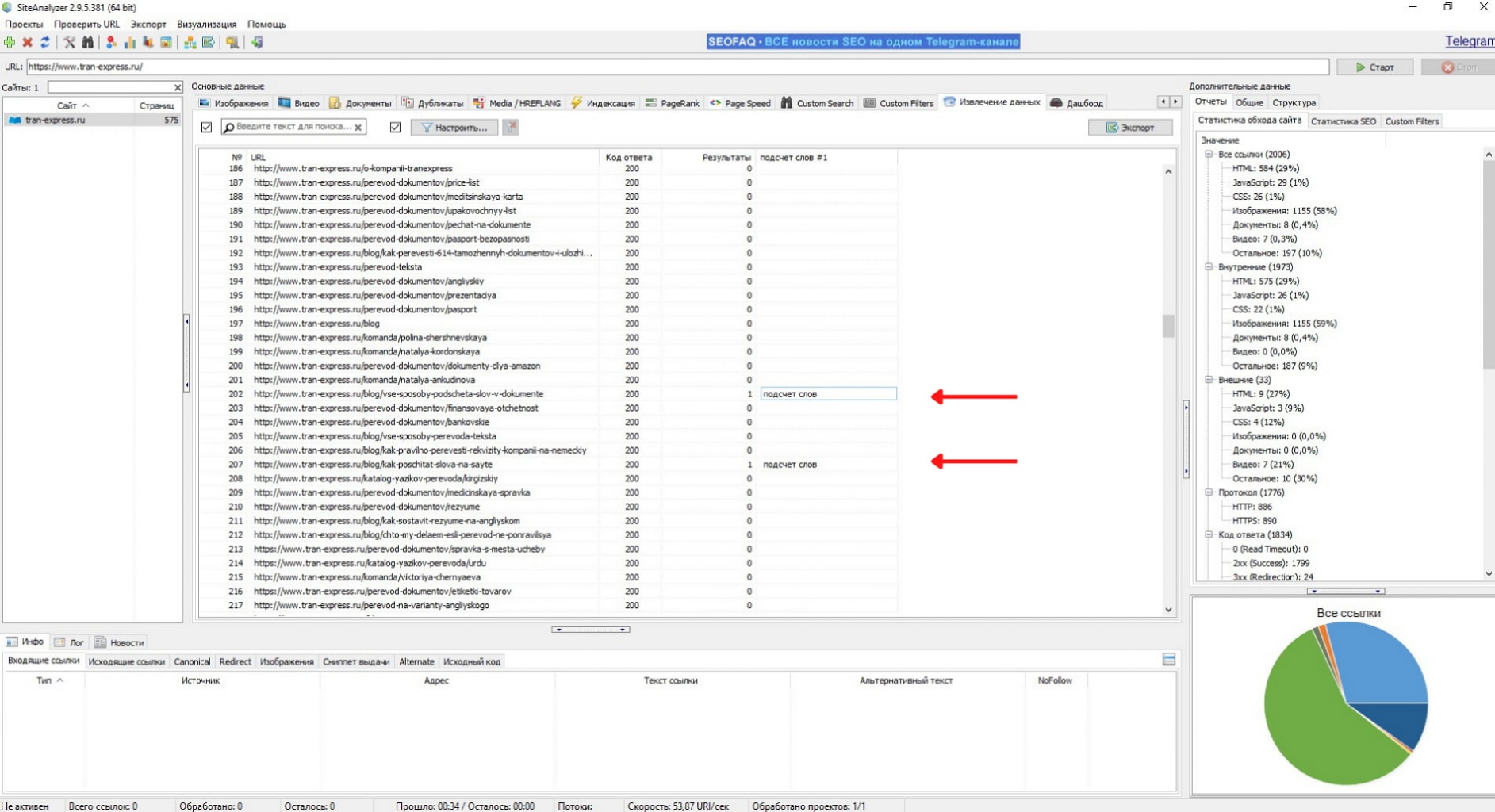
В нашем случае поиск осуществляется только по форме фразы “подсчет слов”. Если нужно найти и другие варианты этого словосочетания, потребуется добавить дополнительные правила.
Screaming Frog SEO Spider
Другая программа - это Screaming Frog SEO Spider. Предоставляет возможность гибкого сканирования сайта и является одним из лидеров сферы. Ознакомиться со всем функционалом можно в документации. Отметим, что программа также является платной и требует ключ активации.
1. Подготовка. Настраиваем "лягушку"
Как и в случае с сайтаналайзером мы можем менять user agent, для беспроблемного парсинга большинства сайтов рекомендуем его поменять сразу.
Запустив программу наводим курсор на "Configuration" и в появившемся меню выбираем на “Crawl config”.
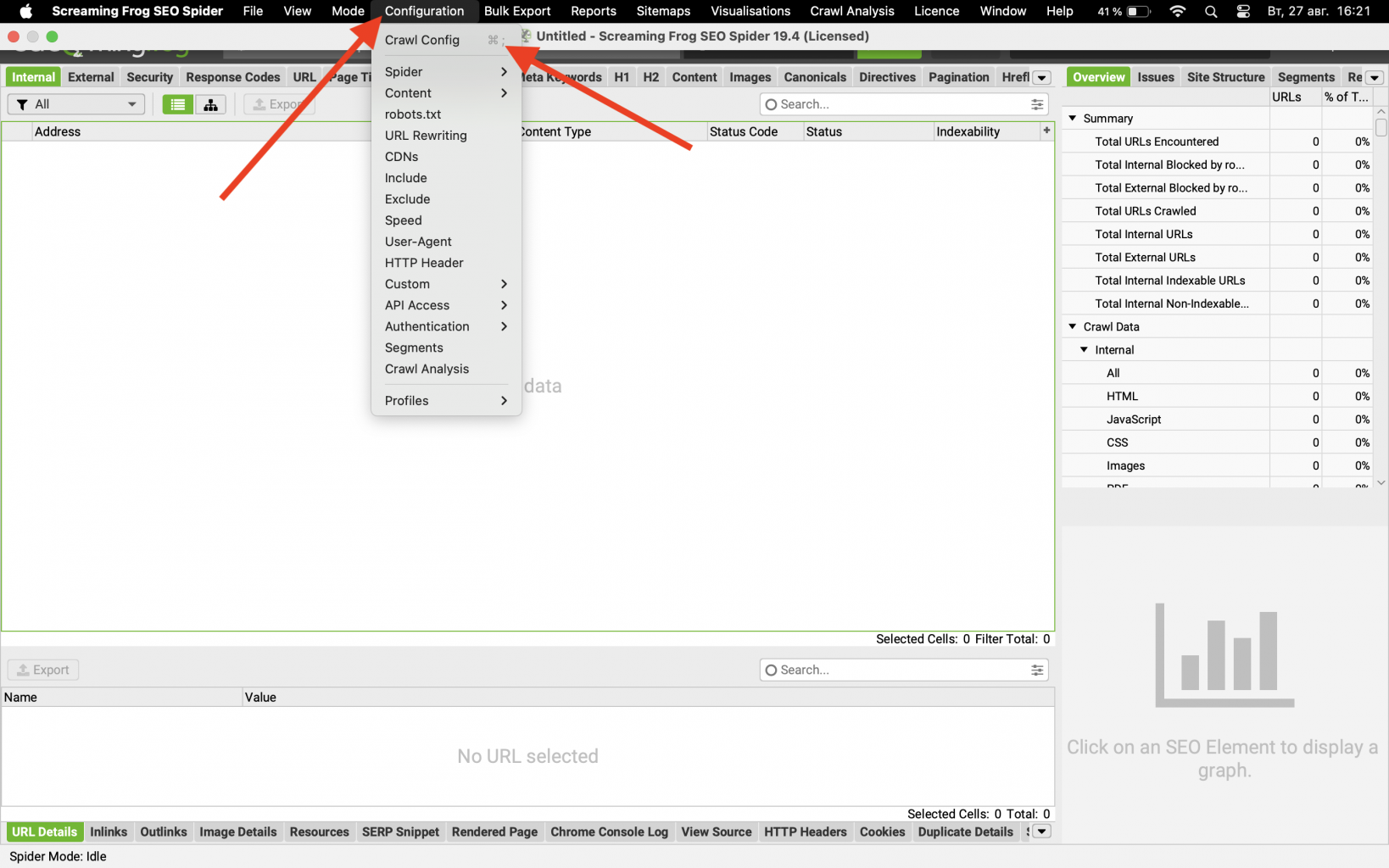
В открывшейся вкладке ищем пункт “User-Agent” и переходим на него. нас интересует выпадающий список Preset User Agents, раскрываем и выбираем DuckDuckBot. Нажимаем “ok”.
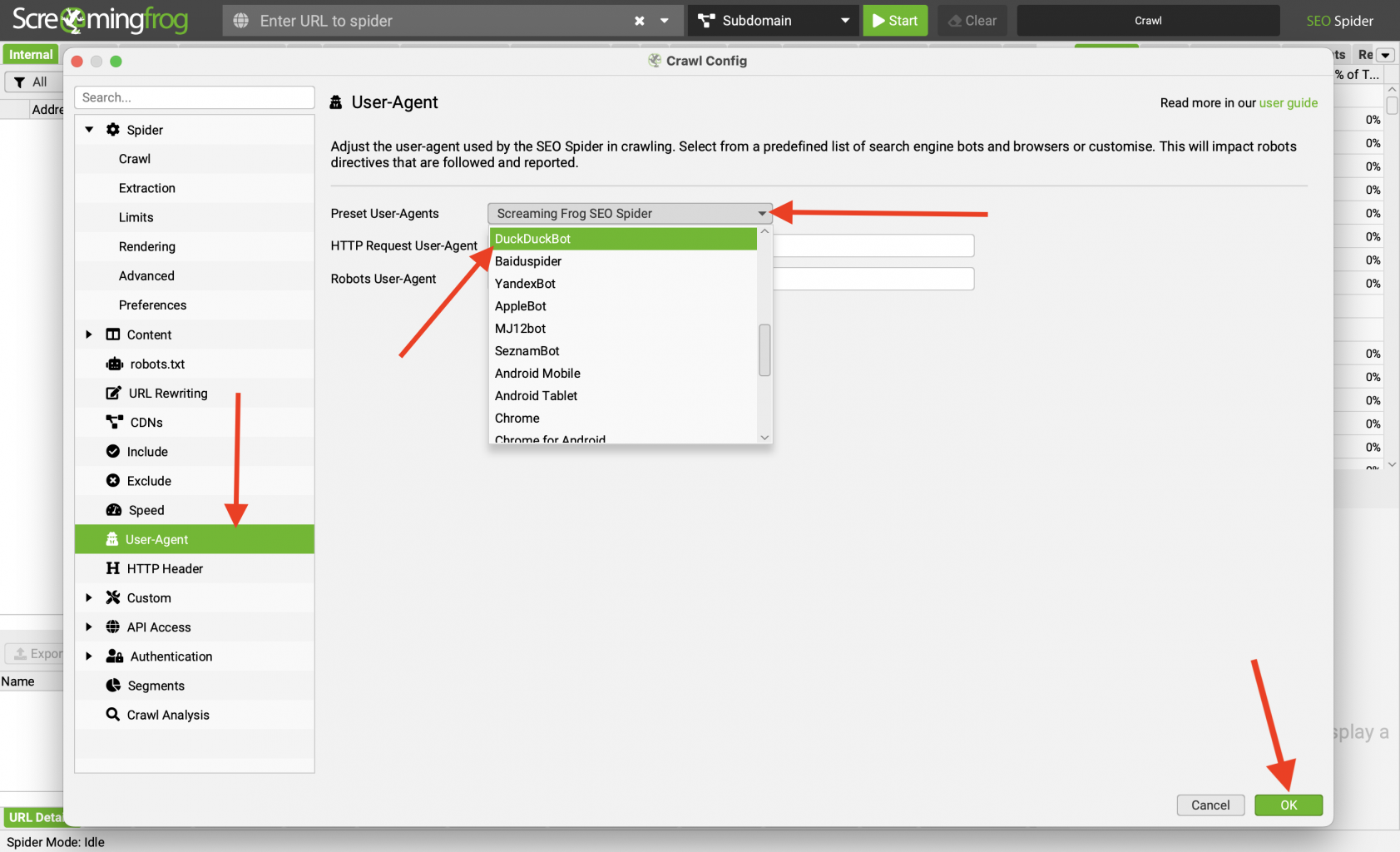
На нашем опыте это самый результативный юзер агент, который парсил без каких-то помех все сайты, которые мы ему скармливали. Но, возможно, что вам он может не подойти. Это зависит от настроек сервера, на котором находиться сайт. Большинство современных серверов имеют защиту от чрезмерных нагрузок (DDOS атак) и просто отклоняют запросы при большой нагрузке, которую также способен создавать парсер. Для обхода этой защиты можно использовать:
- Смену юзер агента, как это делаем мы.
- Корректировку скорости парсинга. Подробно об этом можно почитать у Screaming frog. Этот способ мы тоже использовали, но в нашем случае все решилось через смену агента.
Шаг 2. Определяем правило поиска.
Как и в случае с прошлым парсером для поиска необходимо задать правило.
Screaming Frog является мощным инструментом и кроме уже знакомого RegEx в нем есть отдельный поиск текста, который находиться на вкладке "Custom Search". Не будем углубляться и рассмотрим данный метод только в рамках нашей задачи. Почитать подробнее можно в документации.
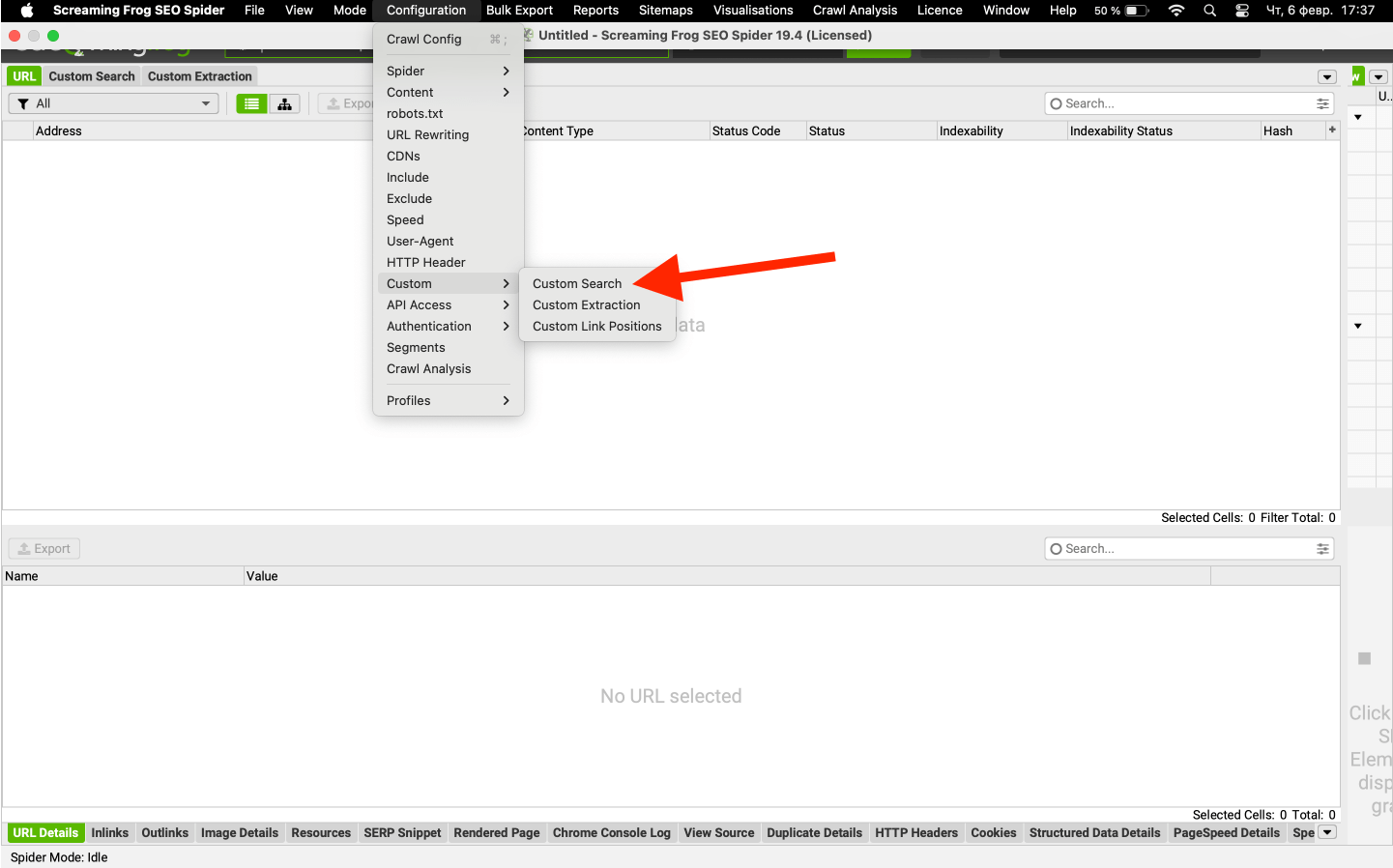
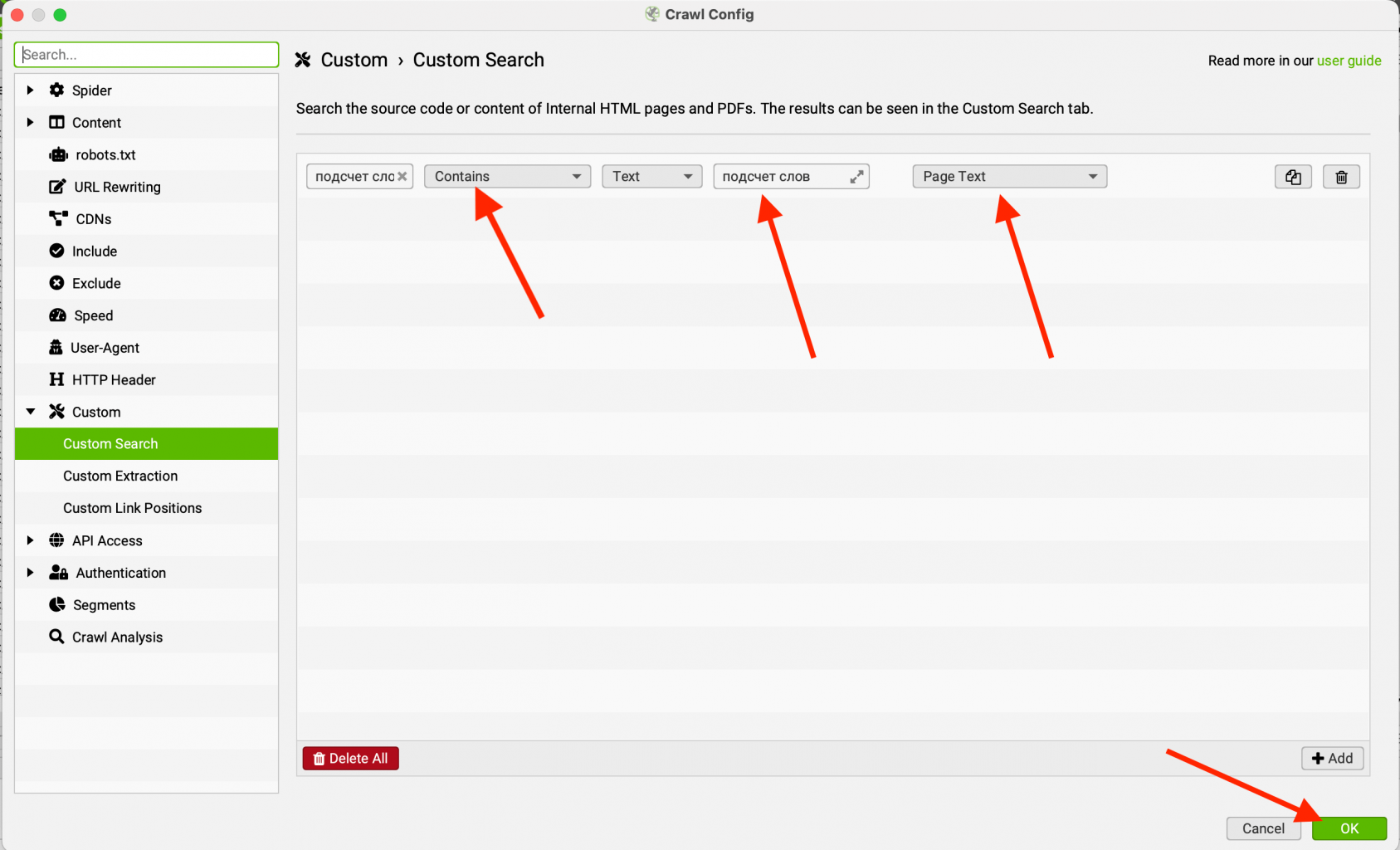
У нас откроется пустая вкладка “Custom Search”. Для добавления поискового поля нажимаем add и в поле будет добавлено дефолтная строка под правило поиска.
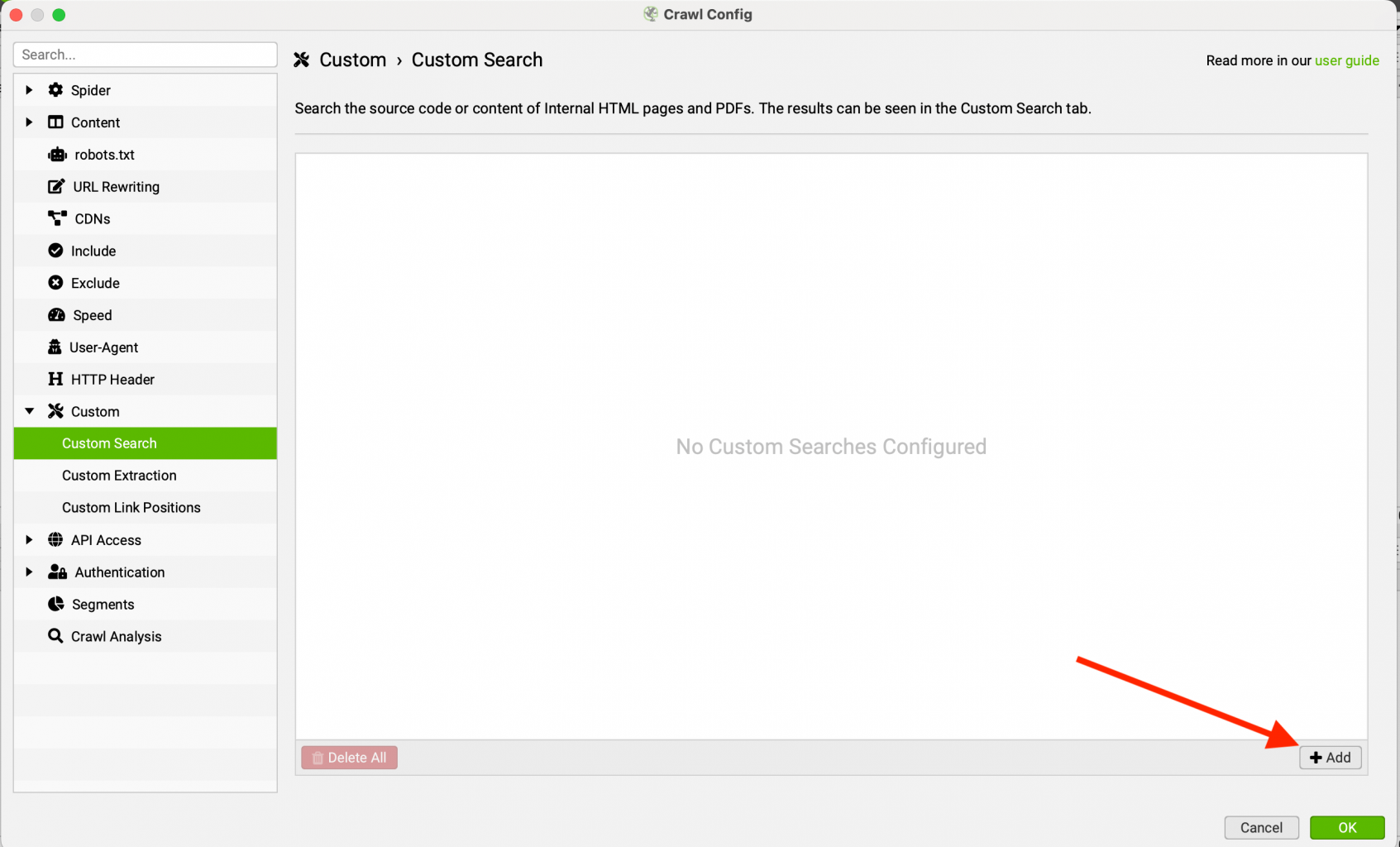
Добавляем правило для поиска, не забываем сохраняться и запускаем парсинг. Немного поясним, что мы указали:
- "Подсчет слов" - первая графа это название правила. Оно будет отображаться в таблице. Название может быть любым и влияет только на отображение результата.
- Contains - формат поиска. Данный вариант означает, что мы ищем все варианты, которые содержат нашу фразу. Если будем использовать "Does Not Contain", то будем искать варианты, в которых установленной фразы нет.
- Text - метод поиска. Ключевое отличие от SiteAnalayzer. Можем использовать, как обычный текстовый поиск, так и RegEx. В данном случае, мы будем использовать именно поиск по тексту.
- "Подсчет слов" - фраза, которую мы ищем.
- Page Text - поиск по тексту на странице.
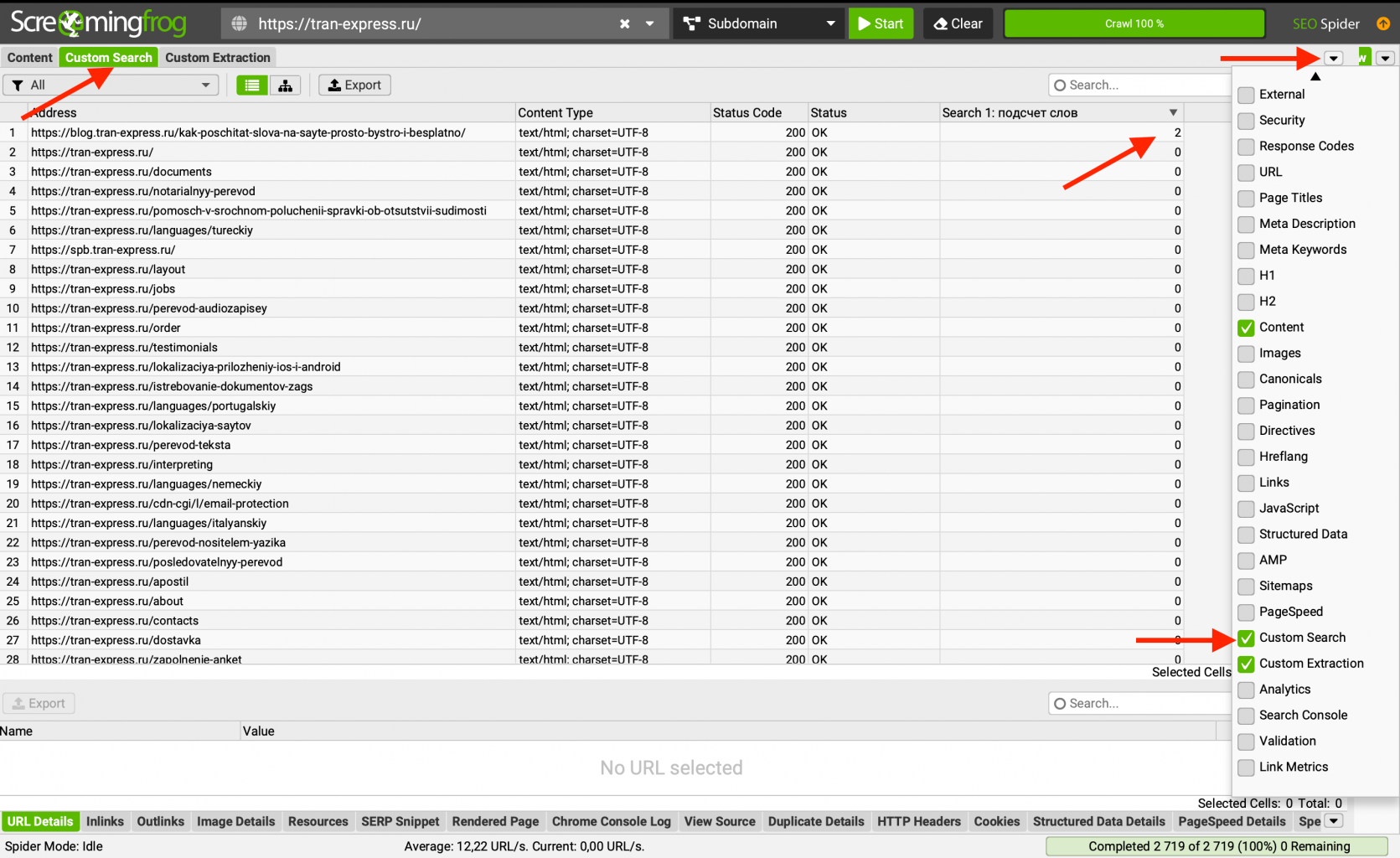
После парсинга мы переходим на вкладку "Custom Search", в которой отображаются результаты. Для удобства на скриншоте мы отключили лишние вкладки, вы тоже можете это сделать, нажав на иконку и отметив то, что хотите видеть на панели.
Сделаем сортировку по количеству вхождений от большего к меньшему и увидим результат.
Используя парсеры, повышайте продуктивность
В данной части мы расмотрели, как найти слово или словосочетание на сайте и какими инструментами это можно сделать.
Рекомендуем при выборе инструмента отталкиваться от целесообразности его использования. Если у вас сайт на 10 страниц и вы понимаете, что нужный элемент встречается в 2-3 местах, то проще будет воспользоваться поисковыми операторами, а если работаете с интернет магазином на 1000 страниц, то без специальных программ тут не обойтись.
